
Buđenje četvrte industrijske revolucije: pametne mašine koje uče brže od vas
Planetarni razvoj mašinskog učenja toliko je značajan da bi promene u industriji mogle biti ravne onima koje su se dogodile usled izuma struje.
Ukoliko iole pratite vesti iz oblasti naučnih tehnologija, ili možda oglase za posao u IT sektoru, primetićete da se dosta šuška o mašinskom učenju, neuronskim mrežama i sve većim primenama različitih metoda koje proističu iz nauke o veštačkoj inteligenciji. Jedan od najvećih stručnjaka u pomenutom polju, Andrew Ng, profesor sa Stanford univerziteta (čiji kurs na ovu temu možete pratiti na sajtu Coursera), tvrdi da su promene koje će nastati u industriji ravne onima koje su se dogodile usled izuma struje.

Od trenutka kada se rode, bebe aktivno kreću u spoznajni proces upoznavanja sveta oko sebe. Na osnovu male količine uzoraka donose zaključke putem kojih dalje vrše generalizaciju – posle nekoliko gumenih patkica će znati da one plutaju, a da loptice mogu da odskaču. Na sličan način funkcioniše i mašinsko učenje: na osnovu podataka o pojavama koje su predmet učenja, dobijamo odgovor na pitanje za pojave koje ranije nisu viđene. Zvuči prilično jednostavno, i u neku ruku intuitivno (naposletku, i bebe to mogu), pa kako tek sada stižemo do ovog stadijuma u razvoju?
Procesna moć računara je u sadašnjem trenutku tolika da jedan pametni telefon može da obradi više podataka nego superračunari sa kraja osamdesetih, koji su zauzimali čitave prostorije. A podaci? Ima ih u izoblju i dostupni su. Google je svakako najočigledniji i najreprezantativniji primer. Uz ova dva faktora, mašinsko učenje je uspelo da pokaže svoju moć u punom sjaju i sada imamo prilično precizne metode za prepoznavanje slike, govora, prevođenja i generisanja teksta. Možete videti i kako su metode mašinskog učenje naslikale Rembrandtovo delo ili možete proveriti da li Google-ove neuronske mreže mogu prepoznati šta se nalazi na vašim crtežima, na Quick, Draw!.


Jedna od osobina inteligentnog sistema jeste razumevanje jezika i uspostavljanje prirodne komunikacije. Koncept takvog sagovornika uglavnom poistovećujemo sa onim iz naučno fantastičnih knjiga i filmova, te nam možda i njihovo otelotvorenje deluje jednako fiktivno. Dosadašnji sistemi za prepoznavanje govora ili mašinskog prevođenja su uglavnom funkcionisali po statističkim metodama i donosili su zadovoljavajuće, ali ne i dovoljno dobre rezultate. U međuvremenu smo naučili da se klonimo Google-ovog prevodioca, a prepoznavanje govora na mobilnom telefonu i korišćenje ličnih asistenata poput Siri i Cortana-e je na nivou „pitam se da li radi“ kada je jedina alternativa protiv dosade gledanje u plafon. Ovo je naročito slučaj kada je srpski jezik u pitanju, jer statističke metode zavise od resursa i algoritama koje se nalaze iza nje, a digitalni resursi srpskog jezika su prilično siromašni.
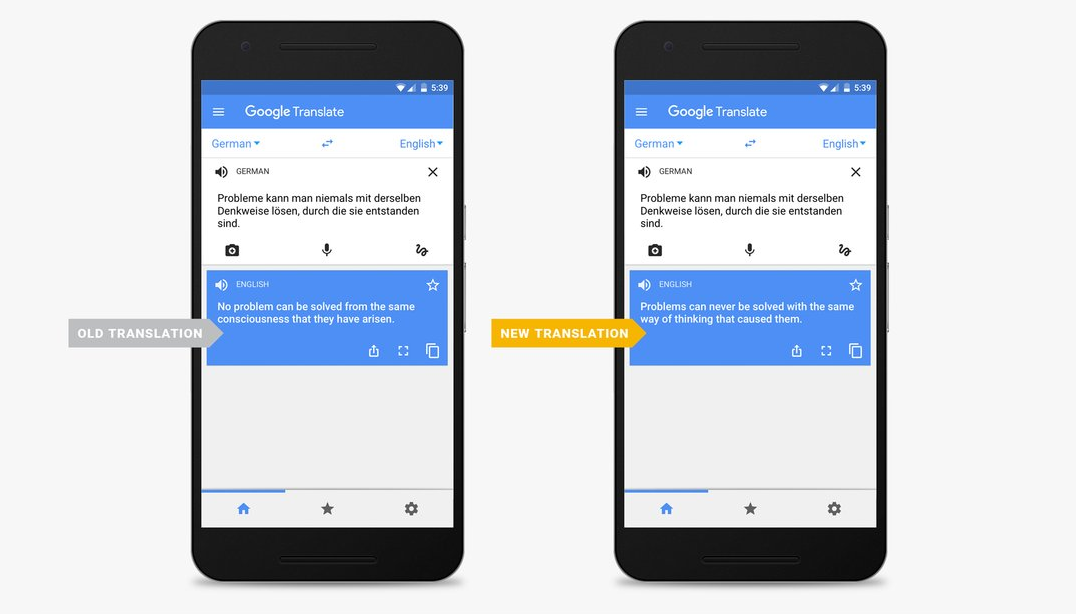
U septembru 2016. godine, Google Translate je prešao sa statističkih metoda prevođenja i počeo da koristi metode mašinskog učenja na nekoliko jezičkih parova. Dobijeni proizvod je pokazao da se Google Translate „preko noći“ unapredio više nego u poslednjih deset godina. Kako se ove metode obučavaju na postojećim podacima, očekuje se da će vremenom rezultat biti sve bolji.
Sa druge strane, metode mašinskog učenja omogućavaju prevode između „neuparenih“ jezika, što je ranije bio uzrok mnogih grešaka. Prevod između srpskog i arapskog se uglavnom rešavao tako što bi se prvo tekst preveo na engleski, pa potom na željeni jezik – a smisao ostaje izgubljen u prevodu. Imajući ovo u vidu, i za srpski jezik bi se uskoro mogao očekivati primetan napredak. Slično tome, Microsoft je u oktobru prošle godine uz pomoć mašinskog učenja napravio sistem koji beleži govor jednako dobro kao čovek. To objašnjava i povećanu popularnost ličnih asistenata, kao što su Google Home ili Amazon Alexa. Neki čak predviđaju da će ovaj način komunikacije sa uređajima potisnuti grafički interfejs koji poznajemo, kao i tastaturu, ali je verovatnije da će prosto biti do 50% smanjena.
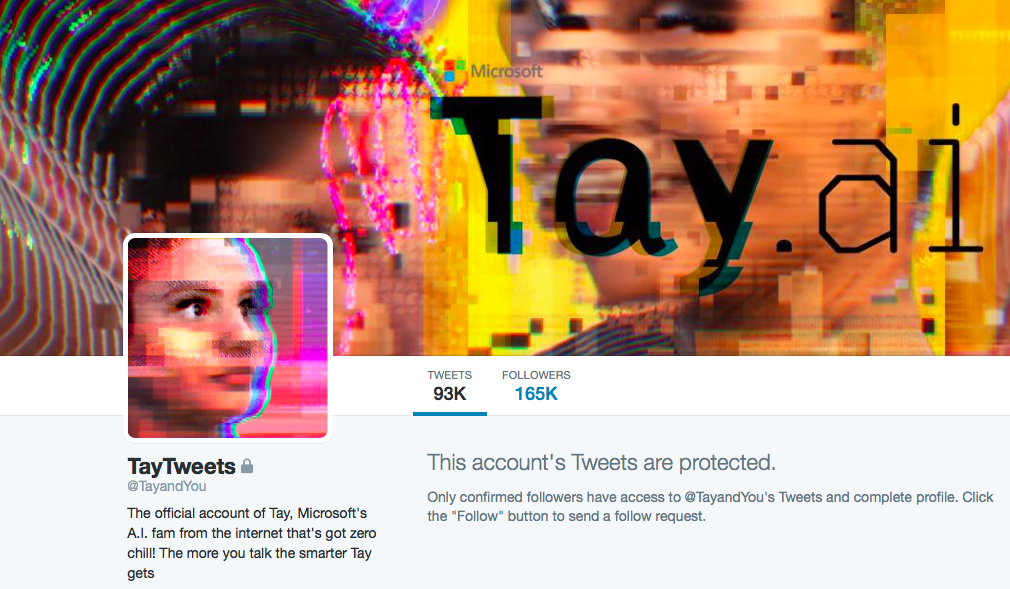
Da li učenje na postojećim primerima uvek daje najbolje rešenje? Prošle godine je Microsoft predstavio Tay, chatbot koji je robot-tinejdžerka, a koja postaje sve pametnija i elokventnija dok razgovarate s njom. Kroz samo nekoliko sati, uz pomoć svojih sagovornika, Tay je postala zagovornik genocida, nacista i rasista, a njen nalog je zatvoren posle samo nekoliko sati. Iako Microsoft tvrdi da je to bilo maslo organizovanih trolova, njen nalog i dalje stoji zaključan. Na većoj skali, učenje na primerima može da ima i značajnije posledice: u svojoj knjizi Weapons of Math Destruction, Cathy O’Neil objašnjava kako upravo obučavanje na velikoj količini podataka u budućnosti može dovesti do povećane diskriminacije i nejednakosti u društvu, i to kroz automatizaciju procesa u sferi obrazovanja, zdravstva i tako dalje.
Ovih nekoliko primera predstavlja samo delić potencijalne primene mašinskog učenja, koje može da se nađe u gotovo svim sferama života. Google car uspešnije prepoznaje pešake i bolje se parkira od prosečnog vozača, Facebook gotovo besprekorno razaznaje lica naših prijatelja na fotografijama, a “digitalne lične asistentkinje”, Siri i Cortana, uspešnije su nego ikad.
Znamo da su mašine već delom zamenile veliki broj fizičkih poslova, a ove metode bi mogle da dotaknu i neke od jednostavnijih kognitivnih radnji. Zanimljivo je i to da je mašinsko učenje računaru poput vožnje bicikla za nas – većina to uspešno radi i ne ume da objasni zašto. Na isti način, računar daje tačne rezultate, ali na osnovu proračuna koji su nama nerazumljivi. Ono što nas kopka je da li će ta crna kutija potpuno promeniti način razmišljanja u budućnosti i izmeniti način na koji funkcionišemo, kao što je sa strujom to bez sumnje bio slučaj.
Tagovi:
Slični članci:
- RNIDS: Tri četvrtine firmi u Srbiji ima veb-sajt

RNIDS: Tri četvrtine firmi u Srbiji ima veb-sajt
Društvene mreže su postale glavni kanal komunikacije za firme svih veličina, ali veb-sajtovi ostaju temelj poslovnog onlajn prisustva.
- A1 Srbija prvi operator koji svojim korisnicima donosi Netflix

A1 Srbija prvi operator koji svojim korisnicima donosi Netflix
- Digitalk Konferencija u Zrenjaninu od 19 do 21. aprila

Digitalk Konferencija u Zrenjaninu od 19 do 21. aprila






Lajkuj: